视觉问答的前世今生
问答(Question Answering, QA) 从20世纪90年代开始,伴随搜索引擎的发展而演进,历经了如下阶段:
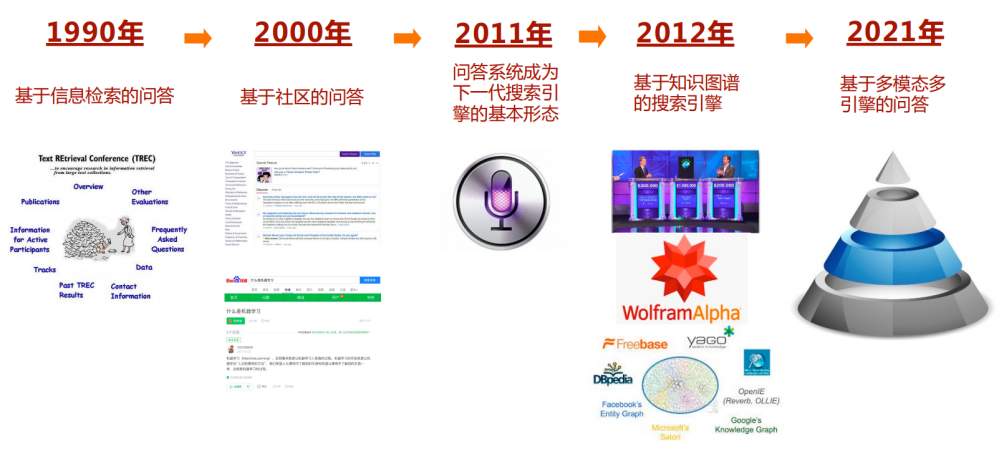
来源:王昊奋,创新+沙龙讲座资料
以基础的关键词搜索为起点,问答开始越来越需要精准的回答。2011年Siri的发布,预示了从PC时代的搜索,向自然语言提问的自然问答阶段转换。此后,谷歌提出了知识图谱的概念,发布了新一代的搜索引擎。知识图谱体量庞大,且持续地进行更新,著名的Wolfram Research推出了WolframAlpha计算引擎,可回答用自然语言提出的问题。问答发展至今,不同的技术具有互补性,相互之间很难完全替代。基于多模态多引擎的问答,就成为了主要的发展趋势。
视觉问答 (Visual Question Answering, VQA) 正是基于问答技术发展而来。它的任务定义是:给定一张图片,提问与图片内容相关的问题,返回自然语言的答案。

来源:王昊奋,创新+沙龙讲座资料
通用领域的视觉问答模型,按照复杂程度可分为3个层次:
- 初级:从图像识别的结果中直接得到答案。目前模型准确率较高,如VQA2.0数据集。
- 中级:答案需要简单实施知识支持。如FVQA数据集。
- 高级:对于复杂的问题,答案不在图像中,可能涉及常识、具体话题和百科知识来进行推理,需要引入外部知识库,如OK-VQA数据集。
医疗视觉问答的当下
2018年,医疗视觉问答任务被首次提出,VQA-Med-2018是第一个医疗视觉问答数据集。它的问题答案对通过半自动方法利用图像标题生成:首先,基于规则,问题生成系统通过句子简化、回答短语识别、问题生成和候选问题排序自动生成可能的问答对。然后,由两名人工注释专家手动检查两遍生成的图像问答对。一遍确保语义的正确性,另一遍确保与相关医学图像的临床相关性。

Medical Visual Question Answering: A Survey. arXiv 2021
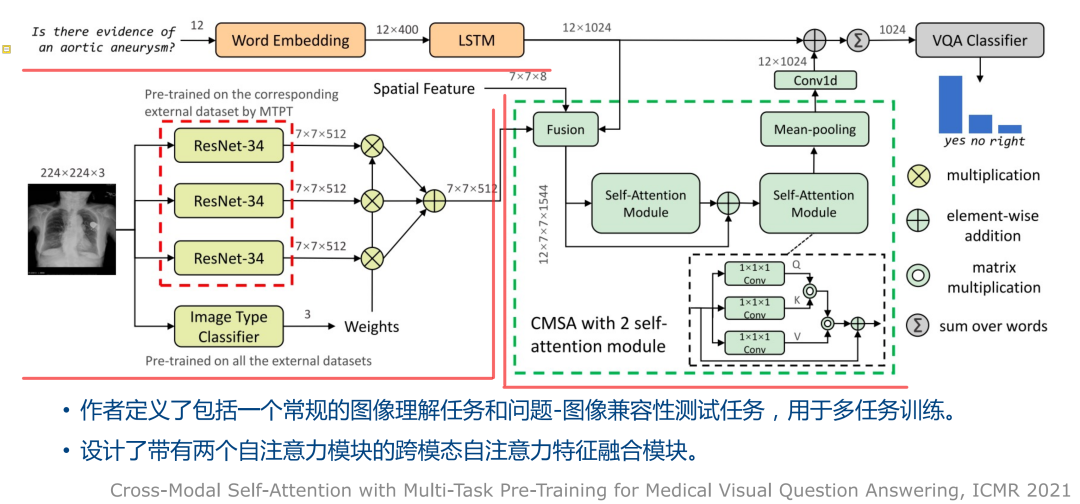
与通用领域相同,医学视觉问答也可以使用预训练加微调的机制,来构建对应的模型。整个过程可以理解为,在预训练过程中习得先验的影视知识,通过下游各种任务上的微调,达到优化处理下游任务性能的效果。可使用的一些方法包括:UNITER,多模态BERT预训练,CLIP对比学习预训练等。
在这个过程中,如果将问题直接编码到低维嵌入空间中,问题嵌入的分布是混乱和不规则的。王教授与其团队通过类型感知的医学视觉问答,对每一种类型的问题嵌入图像标签,添加偏移,实现空间相对独立和更加规则的分布方法。
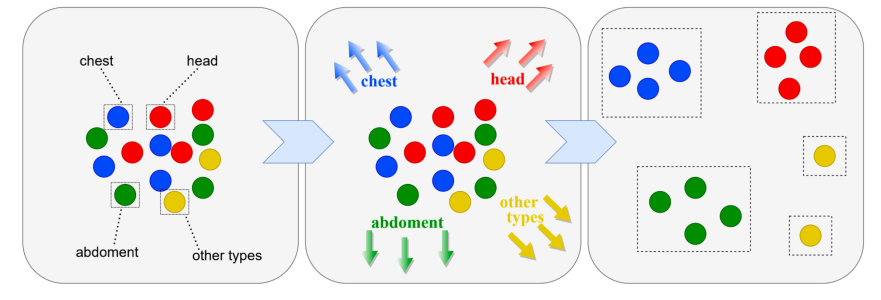
Type-Aware Medical Question Answering, ICASSP 2022
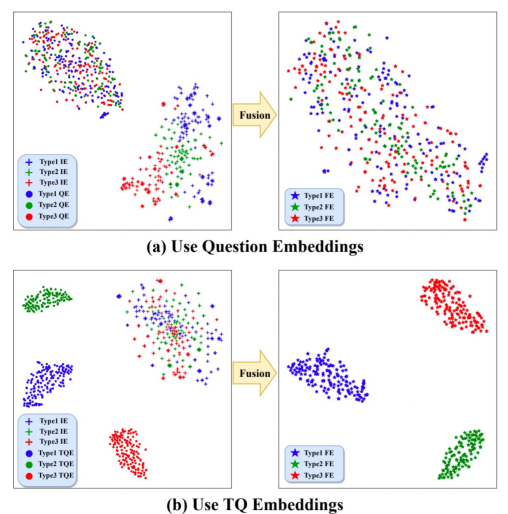
TQ Embedding改善嵌入空间中不同Lable图像和问题的多模态特征表示(Type-Aware Medical Question Answering, ICASSP 2022)
医学视觉问答的展望
相比通用领域,医学视觉问答在技术上更具挑战性:
- 专业知识要求高,专家注释费用昂贵,且无法直接从图像合成问答对。
- 通用领域图像和医学图像存在差异,基于通用领域图形预训练模型的迁移学习在医疗视觉问答任务上的表现有待提升。
- 医疗视觉问答需要聚焦在图像的细粒度上,因为病变是微观的。
从现有技术来说,目前的影像分析模块可以被视为一个Close-end的问答系统,回答影像分类的是/否问题,它的问题类型受限、问题领域受限、推理能力有限。未来的分析将会走向Open-End的模式,回答多医学领域、多影像模态的开放式问题。
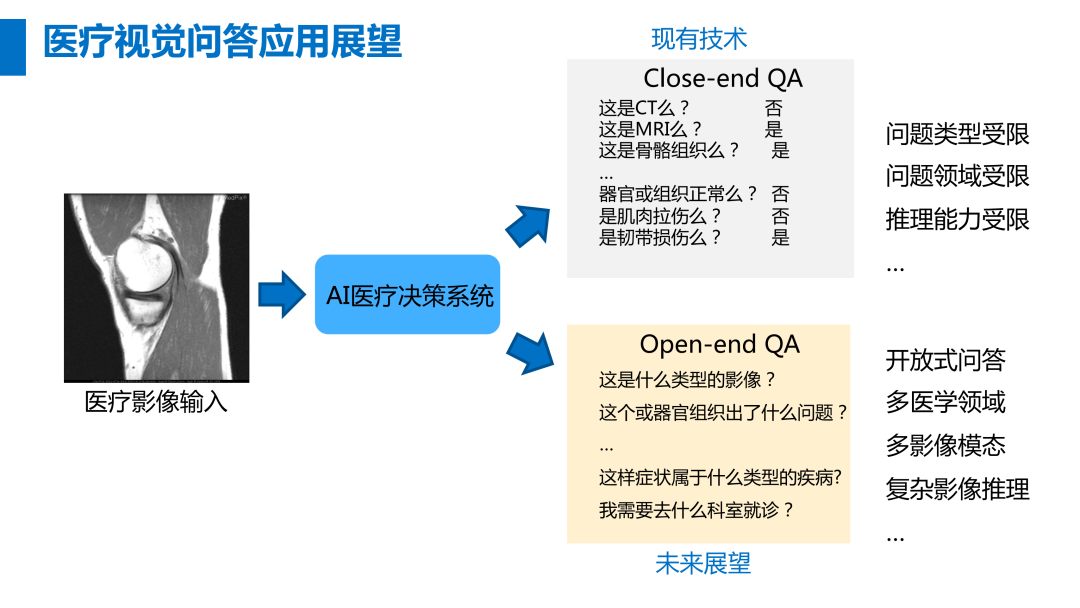
来源:王昊奋,创新+沙龙讲座资料
医疗领域可通过引入外部知识库,如电子病历、知识图谱等,对模型进行优化。另外,医疗领域视觉问答模型的可解释性和可信度是重点问题。在发掘数据规律时,可多采用平衡的数据分布,增加一些正则的模式来缓解单模态下信息偏差的问题。目前来说,深度学习如同一个黑盒,有不可解释性,从建模前、建模中和建模后,透明化一些数据规律,提高模型的可解释性与可信度,也是日后相应研究努力的一个方向。
嘉宾问答
问:视觉问答的数据集是否主要是现有数据集当中的一个分类?目前是否还无法超越给定数据集这个问答范畴?
王教授:VQA是QA的一部分,不过通用领域的一些问答系统已经在发生改变,如将理解型问答和生成型问答结合,或者结合知识库,走生成型的方向,依靠背后的知识库,在数据不完备的情况下,借助外部知识库,来完成给定数据集外的问答任务。它的知识组织未必很好,但它相对更具完整性。视觉问答领域目前还没有走到生成型的阶段,但Open-end的研究将成为一个趋势,开放域会比封闭域更具落地使用的可能性。
问:医疗视觉问答目前还有哪些新的发展趋势?
王教授:一个趋势是,我们在思考医疗视觉问答如何在本国的语言环境下实现应用。如中国健康信息处理会议举办的评测比赛,就涉及VQA在中文环境下的模型训练和开发。另外,由于中文的数据集相对较少,那么就需要研究者思考如何基于小样本或低资源,完成模型的开发训练。跨模态、多语言的模型开发和研究就会成为一个侧重点。
文中使用的图片及资料或已经过授权,或已标注引用来源,其他机构和个人不可擅自用于改编和二次传播。?