精准医学发展与医疗大数据平台的升级
精准医学是医学发展在循证医学之后的革命性变革,以肿瘤治疗为例,传统的肿瘤治疗采用一刀切的方法,对一些患者有效,对另一部分患者却不成功。精准医学采用创新的疾病预防和治疗方法,根据基因、环境和生活方式的个体差异来进行针对性的诊断和治疗,运用影像、分子病理等omics数据的采集和分析进行风险分级,找到治疗靶点,预判治疗手段是否有效。
现有数字化平台以科室为核心,进行了有意义的建设,为精准医学的发展和个性化治疗提供了不少解决方案。但随着精准医学的进步,临床和科研工作中有大量的多模态数据需要处理分析,如何有效地利用这些数据为精准医学服务,对于临床和科研工作来说是非常重要的。
目前大部分医院系统所采用的信息和数据平台架构分散,难以满足精准医学数据存储和分析的需求,基于大数据、人工智能的应用也比较零散,实际过程中遇到了资源无法集中,医疗数据整合困难,人工智能应用面狭窄的问题。医疗大数据,不仅数据量庞大,还有数据增速快、数据类型多样、源于真实世界的特点。
为了更好地处理这些数据,医疗大数据平台应运而生。从数据的应用层次来看,三级医院具备了基础的数据资源整合和应用能力,但对于数据进一步分析处理能力还有待加强。数据整合建设水平提升之后,也面临许多运用数据的挑战:如何进行数据结构化处理、如何运用数据开展专题或疾病的分析,如何让医疗大数据服务于科研,都是未来提升数据应用层次需要解决的难点。
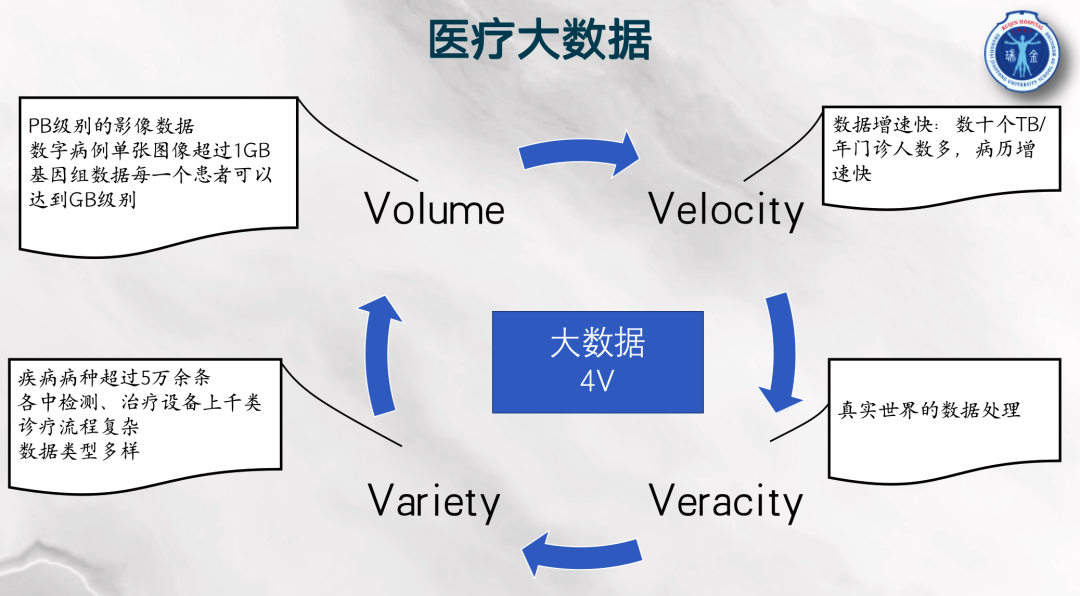
医疗大数据4V特性(来源:温宁,创新+沙龙讲座资料)
突破这些难点,需要数据存储和处理的平台演进升级。数据如同未来数字时代的燃料,数据的精炼就好比产业链的核心,基础设施的建设水平与数据精炼的能力息息相关,涉及数据信任、数据存储、数据转换、数据共享等方面长期的技术和人才沉淀。
以数据的分析和管理应用为例,数据仓库 (Data Warehouse) 在20世纪80年代末已经可以满足基本的数据提取和转换需要,处理结构化的数据。随着非结构化数据的大量增长,数据湖 (Data Lake) 在2011年左右开始被广泛的应用,更好地处理非结构化数据、嫁接机器学习方案。在医疗场景中,数据湖虽适用于实验室类的小型数据处理,但难以像数据库一样满足大型医院的数据处理需求。过去几年中,湖仓一体 (Lakehouse) 的模式逐渐成为主流,它基于数据库的完整架构,可以同时处理非结构化的数据,更能支持机器学习,满足接口与分析(包括实时性分析)的需求。
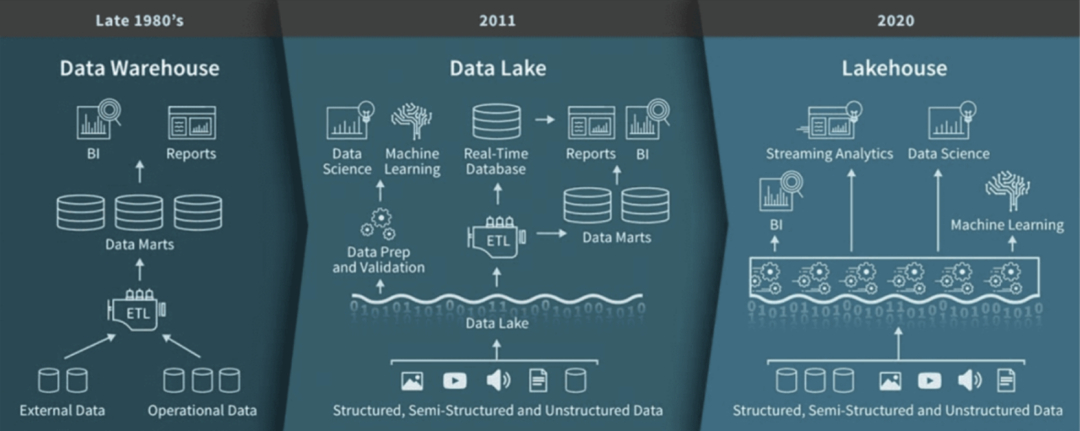
M Armbrust, et al, CIDR 21
构建数据计算平台
医院实际工作中,涉及各种系统,它们的数据各有不同,构建数据中台,需要对大量的结构化、非结构化数据进行提取、调用和转换。由于不同系统之间的管线 (Pipeline) 各有区别,整合数据、统一管理、运用就会有一定的挑战。不少医院已经进行了数据整合管理,在此基础上,为了真正把数据运用起来,建立医院可以应用的数据湖仓,就需要采用工业界严格的数据管理模式(ACID Transactions, Schema Enforcement, Versioning, Streaming, Governance等属性和原则)。
依照严格数据管理模式构建的数据湖仓,将为机器学习、大数据分析和知识图谱建设提供良好的数据平台,支持临床和科研的开发应用。在数据管理过程中,需要考虑六项数据治理原则:
- 元数据:元数据管理是对专病科研元数据、进行盘点、集成和管理,并面向开发人员、医生提供元数据服务,控制数据质量、减少业务术语歧义。
- 数据标准:明确专病数据的数据标准。参考国家标准、行业标准或医院内部标准。
- 数据质量:建立专病数据的数据质量管理体系,实现长效化的数据质量管理机制。
- 数据集成:对专病相关的各类数据进行清洗、转换、整合、模型管理等处理工作。
- 数据交换:专病数据面向不同应用、系统时,对数据的共享、传输交换建立统一的管理机制。
- 数据安全:数据安全应贯穿数据治理全过程。从管理上,建立数据安全管理制度、设定数据安全标准、培养起全员的数据安全意识。从技术上,数据安全包括:数据的存储安全、传输安全和接口安全等。
?依托上述基础,仍需要三个方面的长期投入来支撑数据计算平台的建设:专病知识的长期沉淀,标准化的技术能力,筛查、诊断、预后等分析模型。在数据平台的支撑下,打造适应临床落地的数据生态,则需要数据科学家、算法工程师和临床医生的紧密协同。
数据通用格式和机器学习应用
常规电子病历系统,数据具有时序性,可记录某一时刻发生的事情,模型依据相应的工作场景处理数据。但这种模式并不适应精准医学对数据处理的需求,需要新的数据计算平台塑造以人为中心的关系数据模型。它关注作为个体的患者,每个时间段的信息汇总:患者来到医院后,情况是什么样的,用了什么药,做了什么手术,测量的结果是什么……基于以人为中心的关系数据模型,可以更好地在后期构建以时间节点为主,符合患者特性和精准医学的临床需求的治疗方案。
要构建以人为中心的关系数据模型,自然也涉及文字处理引擎的建设。通过仪表板和数据分析,实现数据的可视化、事件通知传递、实时收集和报告临床信息。其优点主要在于:即便在传统的算法基础上,所有的数据在录入过程中可进行自动化的分类,进而便于后续开展机器学习的分析。
在影像领域,数据准备往往需要花费大量的人员精力,手动构建数据库,找出相关的影像数据和关键信息,再去构建模型。如果有影像数据通用格式,就可以应用结构化报告,增加后续快速、自动化的数据处理,减少人工分析的作业量,进而真正发挥计算机辅助报告、图像标注平台的作用。
如下是一个神经外科胶质瘤的影像分析案例,以患者为中心,贯穿从诊断、治疗、检验检查、治疗方案调整及术后预测等纵向节点上的的分析应用。可以看出,在每一个纵向节点上,都存在着DNA数据、影像数据等大量的多模态数据,数据通用格式对于数据模态转换来说至关重要。各个节点的多模态数据呈几何增长,需要构建具备处理能力的计算平台来支撑数据分析。
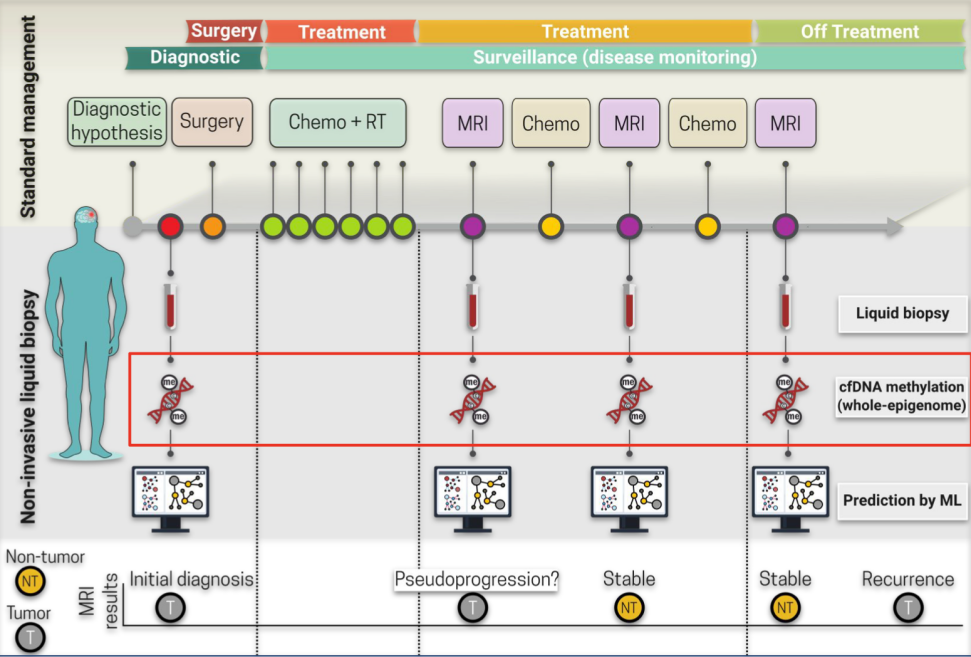
(来源:温宁,创新+沙龙讲座资料)
以Spark分析引擎为例,间接性在内存中的数据计算可以极大地提速。其优点在于改进了数据计算的流程逻辑:流动的不再是数据,而是将处理语言、算法等带入到数据中,建设以数据为核心的平台。如此,可以为算法开发打开更多窗口,第三方也可通过这种新模式,进入医院的数据平台上进行开发。这种形式下,数据无需从医院向外转移,就可以进行实时的、针对病种的数据分析。还可将以动态研发的方式,持续完善深度学习的模型,适应与日俱增的数据量和专业领域的变化,提高临床和科研的工作效率。在自动化更新数据的平台上,研究人员可直接在平台上进行分析和建模,既能避免独立工作站管理不同版本的数据时的问题,又能够更好地完成预后和预测的开发,进而达到指引患者治疗的效果。
从数据治理到模型应用,数据的安全性和隐私性尤为关键。从平台建设开始,就要清晰地界定如下问题:数据将如何使用,用什么规则来转换,谁有权限访问数据,是否会共享数据或产品,是否信任数据的质量,治理权限模型是否可扩展并灵活的设置访问权限。
在明确的数据安全策略基础上,使用者能对数据平台的安全性和可靠性保持较高的信任,有利于进一步开展多院区、疾病联盟范围内的协作研究。而联邦学习架构则可以为协作提供路径借鉴。
在联邦学习架构中,主要的领导者是Aggregator,其他人是Collaborator,不同的角色均可对数据进行各自的处理,在这个过程中,数据无需在Aggregator和Collaborator之间共享,Aggregator在完成数据和模型设置之后,可以通过接口,由Collaborator在平台中运行自己的训练,将完善后的模型返回给Aggregator。在这个过程中,大量的Collaborator同时对数据进行分析建模,可以大大提升模型的完善程度和工作效率。无需共享数据的条件,有利于促成地区和机构之间的合作,模型在不同机构、地区之间的适用性也能得到很好的提升。
构建专病平台,可基于某几种疾病,分阶段设计和建设平台。这是一个庞大的系统工程,需要从小的切入点(如某几个病种)进行专攻,不断做纵向的迭代和深化。这个过程主要涉及以下步骤:
- 数据的清洗和结构化:实现动态检索和表单设计的功能,数据入组可通过手动输入或将以前的数据自动转换的方式实现,满足现下临床和科研的使用需求。
- 数据处理:专注数据处理、数据交换和数据安全能力的建设。开发标准化的可用于数据交换的数据库,自然语言处理模型等,完善安全的数据处理能力。
- 开发数据平台:在标准化的接口上拓展支持主流语言开发的能力,吸引到各个科室和临床科研人员使用计算平台,以规范化的流程,增强算法的应用和开发潜力。
- 扩展应用范围:达到在医联体或区域间的应用,解决更大范围内标准化的接口、授权规则等问题。
嘉宾问答
问:这个数据平台有大量的医疗数据,怎么保证平台的隐私和安全?
温老师:安全性和隐私性是这类数据平台成功与否的核心因素。一种是基于传统的方式,定制模板和报表,让每个医生能够清楚的看到数据的使用情况:包括权限、如何去共享、所有的日志等在内等多个方面。另外,也可以使用区块链的方式,从平台建设之初就进行数据上链的工作。它的好处是所有的Tranasction都是真实记录且不能修改的,也不能对数据进行恶意拷贝。但这个建设的过程需要医工紧密结合,需要工程师和临床医生进行不断的磨合。要采用阶段性的方式,分阶段完成平台建设。
问:以影像专病数据库为例,您觉得最关键的建设挑战是什么?
温老师:一是结构化与半结构化的数据的结合。结构化报告具有便于分析的优点,但高度机器化的报告可能无法适用于医生写报告的想法内容表达。我们在自然语言处理上还是需要很好的功能来结合两种模式。
二是在标注方面,如放疗在图像上的标注。算法模型需要标注,来展开对勾画、体积或者影像组学的数据分析,但对于放射科来说,是不需要额外增加对所有数据的标注工作量的。所以我们在做影像数据的通用格式时,就需要一个模式,能够把相关的数据直接输入转化。这需要多模态数据的处理能力,如把文本的信息和相应的图片信息进行分析整合,这在自然图像领域已经有了比较广的应用,RSNA做了大量的工作,也有免费可使用的资源,作为基础参考来做进一步的开发。
文中使用的图片及资料或已经过授权,或已标注引用来源,其他机构和个人请勿自用于改编和二次传播